
NVIDIAの「Jetson」シリーズはAI(機械学習)処理に適したSBC(シングルボードコンピューター)です。
中身的には普通のSBCとあまり変わりませんが、AI処理に必要なGPUが強化されているのが大きな違いとなります。
「Jetson」シリーズの中でも廉価版に位置づけられるのが「Jetson Nano」で、GPUに128コアの「NVIDIA Maxwell」を内蔵しています。
今回レビューするのはその「Jetson Nano」の互換品となるOKdo「Nano C100」です。
機材を提供いただいたIoT本舗様には、この場をお借りして御礼申し上げます。
OKdo Nano C100

| ■ OKdo Nano C100 | |
| CPU | ARM A57×4コア (1.43GHz) |
|---|---|
| GPU | 128コア Maxwell |
| メモリ | 4GB LPDDR4-3200 |
| ストレージ | 16GB eMMC |
| インターフェース | USB 3.0×4 microUSB×1 HDMI DisplayPort 1GbE 有線LAN microSDXC |
| wi-fi | M.2スロット |
| サイズ | 100×80×29mm |
GoodPoint
✔ Jetson Nanoでできることはほぼできる
✔ 機械学習に対する高いワットパフォーマンス
✔ ストレージ(eMMC)内蔵
BadPoint
✖ 本家より作りがやや甘い
✖ もっと改良点が欲しかった
✖ マニュアルの整備状況がいまいち
✖ 価格メリットが薄い

クーポンコード:GT8DZ12P (一人一点限り)
クーポン期限:5月15日(早期終了の場合あり)
外観

外箱です。

横にスライドさせると中が見えるように

製造担当はradxaのようです。こんなとこでロゴを目にするとは。

全体です。大型のヒートシンクを備えていて、ファンレスで動作します。
後述しますが消費電力が10Wにも満たないからこそできることです。

インターフェースはHDMI+DisplayPort、USB×4、有線LAN。
電源は電源ジャックかmicroUSBを使います。

このピンで電源の切り替えを行います。左が電源ジャック時、右がmicroUSBです。
最初これを忘れていて、なぜか電源が入らないと焦ったのは内緒。

横から見たところ。
ヒートシンクは中央がやや厚めのかまぼこ型。

真上から。
有線LANの後ろの4ピンは冷却ファン用です。

背面にはピン配置が印刷されています。

システムボードを外したところ。
ボードの下にはWi-fi用のカードスロットが隠れていました。

システムボードの背面。
右上にあるのがeMMCチップです。
Jatson Nano(2GB)と比較

本家「Jetson Nano」と互換性がある「Nano C100」ですが、外箱も互換性があります。

「Jetson Nano」は開発者キット(2GB)版なので、「Nano C100」とはカメラインターフェースの数などが違っています。

背面に何もないのは同じですが、「Nano C100」はGPIOの横に合計8個のホールが空いています。使い道は不明です。

微妙に違うのがここ。「Jetson Nano」はシステムボードを支える六角スペーサーがねじ止めされているのに対し、「Nano C100」は穴にはめ込んでいるだけです。
これでも動かないのですが、システムボードを外したときにポロッと落として無くしかけました。
この問題はすでに認識していて、5月以降の販売分についてはねじが付属するとのことです。
2023年5月4日追記:固定ねじが追加されたとのこと。また、改良に合わせてAmazon販売用にクーポンをいただきました(記事上部に掲載)。
本来はこのあとJatson Nano(2GB)とベンチマーク比較をする予定だったのですが、Jatson Nano(2GB)が文鎮化していたので、急遽他のSBCを用意しての比較となりました。
システム
システムを起動するまでは、非常に簡単です。
1.OSイメージファイル(※)をダウンロードする
2.イメージファイルをmicroSDに書き込む
3.本体にいれて起動する。
※「Nano C100」はeMMCがあるのでデバイス番号に違いがあり、「Jetson Nano」向けイメージとは一部異なっている
参考 Nano C100の初期設定:IoT本舗
参考 公式インストールガイド:NVIDIA
参考 Jetson Nano:github
参考 JetPackの過去のバージョンアーカイブ:NVIDIA

公式ガイドではbalenaEtcherでの書き込みを推奨していますが、やってることはLinuxにおけるddコマンドなので、がじぇっとりっぷはRaspberry Pi Imagerを使用しました。

本体に差し込み起動すると、ででんとNVIDIAロゴ。
ブートシークエンスでは「C100」の文字。
初起動時はセットアップ画面が表示されます。
セットアップを進めて起動したところ。デスクトップ画面はこんな感じ。
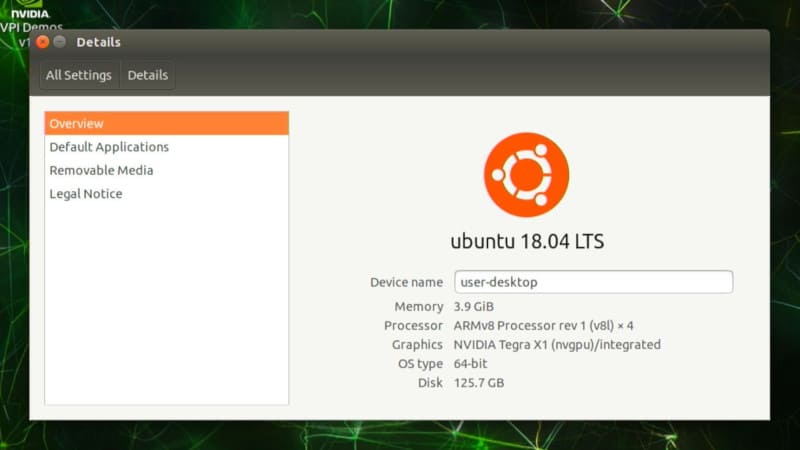
中身はUbuntuです。ベースとなっているOSはUbuntu18.04とかなり古いです。
流石に5年前のOSはどうかと思いますし、Pythonのバージョンも3.6.9で止まっていて、Tensorflowのサポートから外れる寸前なので、ここは更新してほしいですね。
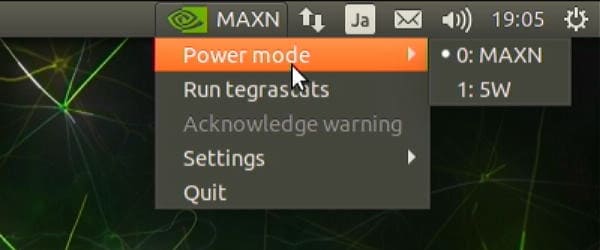
動作モードはMAXN(10W)と5Wを選択できます。
5Wモードでは動作するのが2コアとなり、動作周波数も抑制されます。
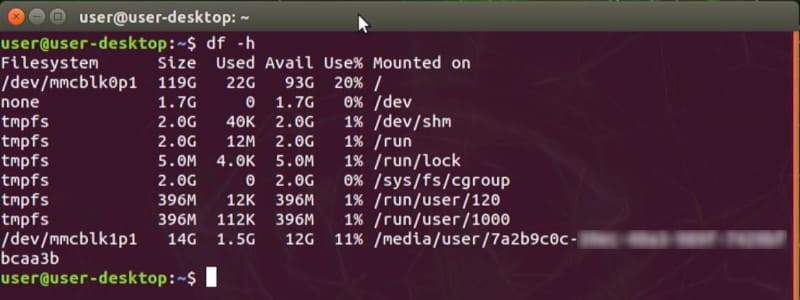
パーティションはこんな感じになっていました。
eMMCから起動すると、CUIが立ち上がります。
が、なぜかIPが割り振られず、microSDでの動作は確認できるとあって、この先の検証はmicroSDで行いました。
もっと簡単にmicroSD経由でeMMC内OSをアップデートできるツールとかあると良かったんですけどね。
ベンチマーク
性能については、いくつかのSBCとベンチマークで比較してみます。
比較に使用したのは以下のSBCです。
| SoC | コア数 | メモリ | OS | |
| Nano C100 | ARM A57 | 4コア | 4GB | Ubuntu 18.04 |
| Raspberry Pi 4 | Bloadcom BCM2711 | 4コア | 4GB | Raspberry Pi OS |
| NanoPC-T4 | Rockchip RK3399 | 6コア | 4GB | Debian 11 |
| Khadas VIM4 | Amlogic A311D2 | 8コア | 8GB | Ubuntu 22.04 |
| Orange Pi 5 | Rockchip RK3588 | 8コア | 16GB | Ubuntu 22.04 |
※Raspberry Pi OSはDebian 11ベース


UNIX Bench
まずは定番のUNIX Benchから。
UNIX Benchは主にCPUの総合性能を測るテストです。
「Nano C100」のCPU部の性能はNanoPC-T4(Rockchip RK3399)と同等程度。ただしRK3399はbig.LITTLE構成なので、シングルスレッドスコアは差を付けられています。
というか、Orange Pi 5(RK3588)すげぇ…
GeekBench
WindowsではおなじみのGeekBenchには、実はARM/RISC-V向けのベータ版が存在します。
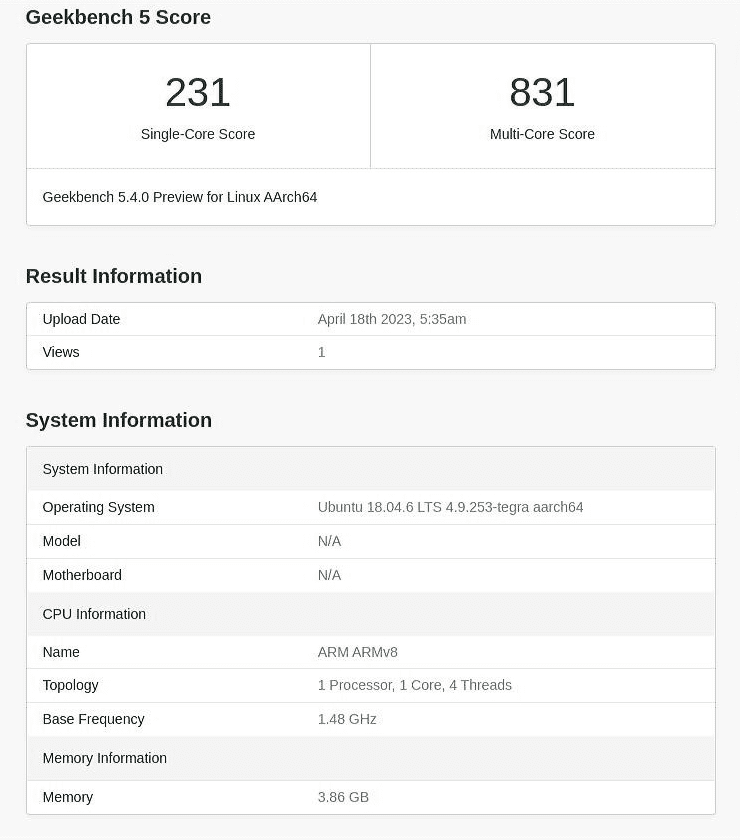
こちらは少々頑張っていて、NanoPC-T4(Rockchip RK3399)を上回っています。Raspverry Pi 4とはシングルスレッド性能は同程度ですが、マルチスレッド性能は差を付けていますね。
PassMark
PassMarkもARM向け版が存在しています。
ダウンロードして解凍、実行するだけのお手軽ベンチマークです。
こちらは逆にNanoPC-T4(Rockchip RK3399)を下回りました。
ベンチマークによって処理の内容や重みづけが異なるので、多少ではありますがそれぞれの性格が出ています。
PassMarkは計測項目にファイルコピーがある=ストレージ性能が大きく影響するとはいえ、Nano C100 (10W)のマルチスレッドスコアとVIM4(A311D2)のシングルスレッドスコアが同じなのはちょっともにょります。
glmark2
続いてはグラフィックベンチマーク。
Linux系では定番の一つで、名前の通りOpenGL 2.0を使用して計測します。
今回はOpenGL ES2.0に対応したglmark2-es2を使用。
なお、Raspverry Pi 4はビルドがうまくいかなかったのでベンチマーク実行を断念しました。
GPUは、CPUとはまた違った結果となりました。
「Nano C100」の得意なCUDAではないのに、VIM4(A311D2)やOrange Pi 5(RK3588)を上回っています。
NanoPC-T4(Rockchip RK3399)はちょっと低すぎるので、ドライバがかみ合っていないのかも。
公式ベンチマーク
Jetsonシリーズは、NVIDIAが公式ベンチマークを用意しています。
基本は手順通りに進めていけば問題ありませんが、実行コマンドはオプションをひとつ追加しないとエラーとなります。
このベンチマークはJetsonシリーズ専用なので、他のSBCのスコアはありません。
// 準備(ユーザー名がuserの場合) $ git clone https://github.com/NVIDIA-AI-IOT/jetson_benchmarks.git $ cd jetson_benchmarks $ mkdir models $ sudo sh install_requirements.sh $ python3 utils/download_models.py --all --csv_file_path ./benchmark_csv/tx2-nano-benchmarks.csv --save_dir /home/user/jetson_benchmarks/models/ // 実行 $ sudo python3 benchmark.py --all --csv_file_path ./benchmark_csv/tx2-nano-benchmarks.csv --jetson_clocks --model_dir /home/user/jetson_benchmarks/models/ --jetson_devkit nano --gpu_freq 921600000 --power_mode 0 --precision fp16

実行中は本体はめちゃくちゃ熱を持ちます。とはいえ動作がカクつくとかの症状は見られませんでした。
| Model | FPS(10W) | FPS(5W) | |
| 0 | inception_v4 | 10.51887 | 7.271097 |
| 1 | vgg19_N2 | 10.57951 | 0 |
| 2 | super_resolution_bsd500 | 15.653746 | 10.961334 |
| 3 | unet-segmentation | 17.991589 | 12.513887 |
| 4 | pose_estimation | 14.809625 | 10.34535 |
| 5 | yolov3-tiny-416 | 47.112377 | 33.736116 |
| 6 | ResNet50_224x224 | 36.531582 | 25.911069 |
| 7 | ssd-mobilenet-v1 | 42.793906 | 29.7478 |
5W動作でも10W動作時の6割から7割程度のスコアとなっています。
MNIST
これが本題。「Nano C100」が得意とする、機械学習系のベンチマークです。
これは正確にはベンチマークではないのですが、実行時間をベンチマークとして利用できます。
MNISTは手書き数字画像60,000枚と、テスト画像10,000枚を集めた画像データセットのことで、機械学習入門としてよく使われます。
// Jetsonシリーズはからあげ(karaage0703)さんのTensorflow構築スクリプトを利用 $ git clone https://github.com/karaage0703/jetson-nano-tools $ cd jetson-nano-tools $ ./install-tensorflow.sh // Jetsonシリーズ以外はpip(Pythonのモジュール管理コマンド)でインストールできる $ apt install python3-pip // SBCはpipが入っていないことが多い $ pip3 install tensorflow // MNISTの実行サンプルをダウンロード $ git clone https://github.com/tak6uch1/cuda-tensorflow $ cd cuda-tensorflow/work // 実行 $ time python3 mnist_cnn.py
| real | user | sys | |
| Nano C100 (10W) | 15m10.772s | 3m42.880s | 1m5.808s |
| Nano C100 (5W) | 16m39.168s | 4m6.824s | 1m9.344s |
| Raspberry Pi 4 | 76m37.802s | 280m51.968s | 6m19.475s |
| NanoPC-T4 | 82m15.243s | 363m56.141s | 10m1.196s |
| VIM4 | 29m32.821s | 185m41.339s | 4m49.974s |
| Orange Pi 5 | 17m57.737s | 106m57.667s | 3m47.545s |
timeコマンドは以下のように見ます。
real:実際にかかった時間
user:プログラムの処理時間(各CPUコアの積算)
sys:プログラムに絡んでプログラム以外にCPUを浸かった時間
CPUコアの使用時間なので、GPUで計算した「Nano C100」はuserの項目が極端に少ないです。
CPUで処理している他のSBCはやはり効率はあまりよくありません。
5Wモードと10Wモードはほとんど変わらない処理時間です。
なぜかというと、5WモードはあくまでCPU部分の話で、GPU部分は対象外というか、実際に計測したら6.9Wくらい出ていました。トンチか。
高スペックなRockchip RK3588を搭載したOrange Pi 5は「Nano C100」に迫る処理時間ですが、CPUをぶん回すので消費電力が10Wオーバーに。ワットパフォーマンスという点では「Nano C100」に軍配が上がりました。
ストレージベンチ(fio)
あまり見かけないストレージベンチも実行。
これは「Nano C100」のみの計測です。
計測に際しての設定などは以下の記事に掲載しています。

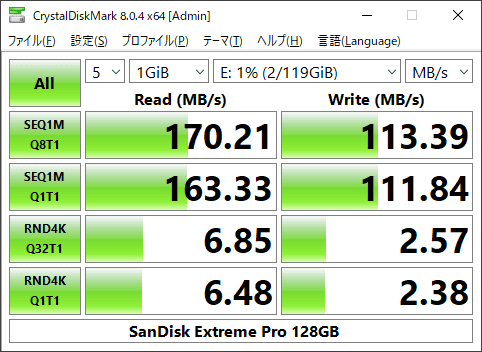
また、使用したmicroSDはSanDisk「Extreme Pro (128GB)」で、シーケンシャルリード170MB/s、シーケンシャルライト113MB/sと高速なモデルです。
microSD
user@user-desktop:~$ TARGET=/home/user/ fio -f fio.txt --output-format=terse | awk -F ';' '{printf "%s: %s MB/s\n", $3, ($7+$48) / 1000}'
Seq1M-Read-Q8: 22.617 MB/s
Seq1M-Write-Q8: 20.355 MB/s
Seq1M-Read: 20.054 MB/s
Seq1M-Write: 18.151 MB/s
Rand-Read-4K-Q32: 7.642 MB/s
Rand-Write-4K-Q32: 2.405 MB/s
Rand-Read-4K: 4.943 MB/s
Rand-Write-4K: 1.309 MB/s
内蔵eMMC
user@user-desktop:~$ TARGET=/media/user/7a2b9c0c-xxxx-xxxx-xxxx/home/nano/ fio -f fio.txt --output-format=terse | awk -F ';' '{printf "%s: %s MB/s\n", $3, ($7+$48) / 1000}'
Seq1M-Read-Q8: 303.935 MB/s
Seq1M-Write-Q8: 62.156 MB/s
Seq1M-Read: 176.706 MB/s
Seq1M-Write: 44.818 MB/s
Rand-Read-4K-Q32: 22.384 MB/s
Rand-Write-4K-Q32: 4.782 MB/s
Rand-Read-4K: 12.017 MB/s
Rand-Write-4K: 2.74 MB/s
ストレージベンチ(PiBenchmarks)
PiBenchmarksはRaspberry Pi向けのストレージベンチですが、他のSBCでも問題なく使えます。
microSD
Category Test Result
HDParm Disk Read 21.36 MB/s
HDParm Cached Disk Read 21.33 MB/s
DD Disk Write 20.0 MB/s
FIO 4k random read 2155 IOPS (8620 KB/s)
FIO 4k random write 805 IOPS (3220 KB/s)
IOZone 4k read 6335 KB/s
IOZone 4k write 1891 KB/s
IOZone 4k random read 5430 KB/s
IOZone 4k random write 2614 KB/s
Score: 932
eMMC
Category Test Result
HDParm Disk Read 193.14 MB/s
HDParm Cached Disk Read 204.34 MB/s
DD Disk Write 62.9 MB/s
FIO 4k random read 5995 IOPS (23981 KB/s)
FIO 4k random write 1353 IOPS (5414 KB/s)
IOZone 4k read 13880 KB/s
IOZone 4k write 3756 KB/s
IOZone 4k random read 16209 KB/s
IOZone 4k random write 5531 KB/s
Score: 2397
消費電力

最後に消費電力を見てみます。
測定はアイドル状態とGeekBench測定時(シングル/マルチ)。また、VIM4のみ組み込みの冷却ファン込みの消費電力となります。
| アイドル | シングルスレッド | マルチスレッド | |
| Nano C100 (10W) | 3.0 W | 4.6 W | 9.2 W |
| Nano C100 (5W) | 3.0 W | 3.6 W | 4.7 W |
| Raspberry Pi 4 | 4.7 W | 6.4 W | 8.6 W |
| NanoPC-T4 | 2.8 W | 6.8 W | 8.7 W |
| VIM4 | 4.1 W | 6.1 W | 10.4 W |
| Orange Pi 5 | 2.9 W | 6.1 W | 14.6 W |
CPU動作に限っては、5Wモードだときっちり5W内に納まっています。
とはいえ、消費電力半分で、性能は1/3以下になるので、普段は10W(MAXN)モードで問題なさそうです。
まとめ
「Nano C100」は「Jetson Nano」互換品の名の通り、機械学習系に対しては高いワットパフォーマンスを持つことが示されました。
AI系においてどこまで高効率化できるかってのは、一つの命題です。
例えば自動運転を例にとると、車載コンピューターという限られたリソースと電力の中で、高速運転下でも問題ない速度での解析と制御が求められます。
入門向けとされる「Jetson Nano/Nano C100」は”開発キット”と呼ばれる通り、基本的にはソフト開発と動作確認の用途がメインで、本番は強力なマシンでぶん回すというのが本筋なのでしょうが、あえてリソースが制限された状況下での学習・推定を行うという用途にも使えそうです。
「Nano C100」の価格は記事執筆時点で23,580円。
ただ本家「Jetson Nano」が24,980円なので、eMMC搭載とはいえ価格メリットが薄いんですよね。
それから、マニュアルがほぼない点も問題です。eMMC起動時の説明がないのは結構困りました。
さらに説明がないからボード上の追加要素っぽい部分はすべて死に要素になっています。
基板を見比べる限りでは設計がシンプルになっている(=故障の要素が減っている)のはメリットですが、ユーザーには伝わりにくい部分です。eMMCが追加されたことでUSBブートもしづらく(U-Bootの書き換えが必要)なっていますし。
互換だけど電源ボタンを追加して使いやすくしたとか、もっと排熱効率のいいヒートシンクにするとか、分かりやすいメリットが欲しかったところです。
それらを踏まえたうえで、今のところの一番の役割は、本家Jetson一択だった市場に選択肢を加えることで、市場独占からの値上げに対する牽制と言ったところでしょうか。
マニュアルが充実していれば評価も変わったと思うんですけどね…
関連リンク
付録:ベンチマーク各種の全体ログ
PassMark
10W
PassMark PerformanceTest Linux
NVIDIA Jetson Nano Developer Kit
Cortex-A57 (aarch64)
4 cores @ 1479 MHz | 3.9 GiB RAM
Number of Processes: 4 | Test Iterations: 1 | Test Duration: Medium
--------------------------------------------------------------------------
CPU Mark: 987
Integer Math 9612 Million Operations/s
Floating Point Math 2578 Million Operations/s
Prime Numbers 6.9 Million Primes/s
Sorting 3879 Thousand Strings/s
Encryption 266 MB/s
Compression 6933 KB/s
CPU Single Threaded 330 Million Operations/s
Physics 128 Frames/s
Extended Instructions (NEON) 573 Million Matrices/s
Memory Mark: 589
Database Operations 820 Thousand Operations/s
Memory Read Cached 4996 MB/s
Memory Read Uncached 3624 MB/s
Memory Write 5628 MB/s
Available RAM 977 Megabytes
Memory Latency 151 Nanoseconds
Memory Threaded 6815 MB/s
--------------------------------------------------------------------------
5W
PassMark PerformanceTest Linux
NVIDIA Jetson Nano Developer Kit
Cortex-A57 (aarch64)
4 cores @ 1479 MHz | 3.9 GiB RAM
Number of Processes: 2 | Test Iterations: 1 | Test Duration: Medium
--------------------------------------------------------------------------
CPU Mark: 327
Integer Math 3060 Million Operations/s
Floating Point Math 819 Million Operations/s
Prime Numbers 3.5 Million Primes/s
Sorting 1298 Thousand Strings/s
Encryption 82.0 MB/s
Compression 2279 KB/s
CPU Single Threaded 215 Million Operations/s
Physics 52.7 Frames/s
Extended Instructions (NEON) 182 Million Matrices/s
Memory Mark: 485
Database Operations 288 Thousand Operations/s
Memory Read Cached 3307 MB/s
Memory Read Uncached 3074 MB/s
Memory Write 3600 MB/s
Available RAM 2088 Megabytes
Memory Latency 163 Nanoseconds
Memory Threaded 4367 MB/s
--------------------------------------------------------------------------
UNIX Bench
10W
========================================================================
BYTE UNIX Benchmarks (Version 5.1.3)
System: user-desktop: GNU/Linux
OS: GNU/Linux -- 4.9.299-tegra -- #1 SMP PREEMPT Tue Nov 22 09:24:39 PST 2022
Machine: aarch64 (aarch64)
Language: en_US.utf8 (charmap="UTF-8", collate="UTF-8")
CPU 0: ARMv8 Processor rev 1 (v8l) (38.4 bogomips)
CPU 1: ARMv8 Processor rev 1 (v8l) (38.4 bogomips)
CPU 2: ARMv8 Processor rev 1 (v8l) (38.4 bogomips)
CPU 3: ARMv8 Processor rev 1 (v8l) (38.4 bogomips)
20:02:46 up 1 day, 22 min, 1 user, load average: 1.48, 1.73, 1.38; runlevel 2023-04-16
------------------------------------------------------------------------
Benchmark Run: 月 4月 17 2023 20:02:46 - 20:30:51
4 CPUs in system; running 1 parallel copy of tests
Dhrystone 2 using register variables 13630644.4 lps (10.0 s, 7 samples)
Double-Precision Whetstone 1490.2 MWIPS (9.9 s, 7 samples)
Execl Throughput 702.1 lps (29.9 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 173237.9 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 48876.2 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 506535.4 KBps (30.0 s, 2 samples)
Pipe Throughput 348739.9 lps (10.0 s, 7 samples)
Pipe-based Context Switching 49532.4 lps (10.0 s, 7 samples)
Process Creation 595.7 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 2905.0 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 1005.3 lpm (60.0 s, 2 samples)
System Call Overhead 356940.4 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 13630644.4 1168.0
Double-Precision Whetstone 55.0 1490.2 270.9
Execl Throughput 43.0 702.1 163.3
File Copy 1024 bufsize 2000 maxblocks 3960.0 173237.9 437.5
File Copy 256 bufsize 500 maxblocks 1655.0 48876.2 295.3
File Copy 4096 bufsize 8000 maxblocks 5800.0 506535.4 873.3
Pipe Throughput 12440.0 348739.9 280.3
Pipe-based Context Switching 4000.0 49532.4 123.8
Process Creation 126.0 595.7 47.3
Shell Scripts (1 concurrent) 42.4 2905.0 685.2
Shell Scripts (8 concurrent) 6.0 1005.3 1675.4
System Call Overhead 15000.0 356940.4 238.0
========
System Benchmarks Index Score 342.6
------------------------------------------------------------------------
Benchmark Run: 月 4月 17 2023 20:30:51 - 20:59:03
4 CPUs in system; running 4 parallel copies of tests
Dhrystone 2 using register variables 54067769.8 lps (10.0 s, 7 samples)
Double-Precision Whetstone 5908.8 MWIPS (9.9 s, 7 samples)
Execl Throughput 2601.0 lps (29.9 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 668991.4 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 190103.9 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 1821033.9 KBps (30.0 s, 2 samples)
Pipe Throughput 1389668.3 lps (10.0 s, 7 samples)
Pipe-based Context Switching 157041.2 lps (10.0 s, 7 samples)
Process Creation 8702.0 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 7483.5 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 1061.5 lpm (60.1 s, 2 samples)
System Call Overhead 1420539.1 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 54067769.8 4633.1
Double-Precision Whetstone 55.0 5908.8 1074.3
Execl Throughput 43.0 2601.0 604.9
File Copy 1024 bufsize 2000 maxblocks 3960.0 668991.4 1689.4
File Copy 256 bufsize 500 maxblocks 1655.0 190103.9 1148.7
File Copy 4096 bufsize 8000 maxblocks 5800.0 1821033.9 3139.7
Pipe Throughput 12440.0 1389668.3 1117.1
Pipe-based Context Switching 4000.0 157041.2 392.6
Process Creation 126.0 8702.0 690.6
Shell Scripts (1 concurrent) 42.4 7483.5 1765.0
Shell Scripts (8 concurrent) 6.0 1061.5 1769.2
System Call Overhead 15000.0 1420539.1 947.0
========
System Benchmarks Index Score 1262.7
5W
========================================================================
BYTE UNIX Benchmarks (Version 5.1.3)
System: user-desktop: GNU/Linux
OS: GNU/Linux -- 4.9.253-tegra -- #1 SMP PREEMPT Sat Feb 19 08:59:22 PST 2022
Machine: aarch64 (aarch64)
Language: en_US.utf8 (charmap="UTF-8", collate="UTF-8")
CPU 0: ARMv8 Processor rev 1 (v8l) (38.4 bogomips)
CPU 1: ARMv8 Processor rev 1 (v8l) (38.4 bogomips)
05:54:31 up 1 day, 1:46, 1 user, load average: 0.96, 0.74, 0.37; runlevel 2023-04-18
------------------------------------------------------------------------
Benchmark Run: 水 4月 19 2023 05:54:31 - 06:22:41
2 CPUs in system; running 1 parallel copy of tests
Dhrystone 2 using register variables 8658216.9 lps (10.0 s, 7 samples)
Double-Precision Whetstone 947.2 MWIPS (9.9 s, 7 samples)
Execl Throughput 449.5 lps (29.9 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 123543.2 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 33568.7 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 356416.0 KBps (30.0 s, 2 samples)
Pipe Throughput 221761.1 lps (10.0 s, 7 samples)
Pipe-based Context Switching 37838.8 lps (10.0 s, 7 samples)
Process Creation 1826.2 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 1742.1 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 352.4 lpm (60.1 s, 2 samples)
System Call Overhead 229569.6 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 8658216.9 741.9
Double-Precision Whetstone 55.0 947.2 172.2
Execl Throughput 43.0 449.5 104.5
File Copy 1024 bufsize 2000 maxblocks 3960.0 123543.2 312.0
File Copy 256 bufsize 500 maxblocks 1655.0 33568.7 202.8
File Copy 4096 bufsize 8000 maxblocks 5800.0 356416.0 614.5
Pipe Throughput 12440.0 221761.1 178.3
Pipe-based Context Switching 4000.0 37838.8 94.6
Process Creation 126.0 1826.2 144.9
Shell Scripts (1 concurrent) 42.4 1742.1 410.9
Shell Scripts (8 concurrent) 6.0 352.4 587.3
System Call Overhead 15000.0 229569.6 153.0
========
System Benchmarks Index Score 245.0
------------------------------------------------------------------------
Benchmark Run: 水 4月 19 2023 06:22:41 - 06:51:11
2 CPUs in system; running 2 parallel copies of tests
Dhrystone 2 using register variables 17194936.9 lps (10.0 s, 7 samples)
Double-Precision Whetstone 1836.4 MWIPS (10.1 s, 7 samples)
Execl Throughput 879.7 lps (29.8 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 231247.4 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 65717.5 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 705858.6 KBps (30.0 s, 2 samples)
Pipe Throughput 439379.1 lps (10.0 s, 7 samples)
Pipe-based Context Switching 51863.8 lps (10.0 s, 7 samples)
Process Creation 3374.0 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 2698.2 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 351.7 lpm (60.2 s, 2 samples)
System Call Overhead 453016.9 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 17194936.9 1473.4
Double-Precision Whetstone 55.0 1836.4 333.9
Execl Throughput 43.0 879.7 204.6
File Copy 1024 bufsize 2000 maxblocks 3960.0 231247.4 584.0
File Copy 256 bufsize 500 maxblocks 1655.0 65717.5 397.1
File Copy 4096 bufsize 8000 maxblocks 5800.0 705858.6 1217.0
Pipe Throughput 12440.0 439379.1 353.2
Pipe-based Context Switching 4000.0 51863.8 129.7
Process Creation 126.0 3374.0 267.8
Shell Scripts (1 concurrent) 42.4 2698.2 636.4
Shell Scripts (8 concurrent) 6.0 351.7 586.2
System Call Overhead 15000.0 453016.9 302.0
========
System Benchmarks Index Score 429.3
glmark2-es2
10W
=======================================================
glmark2 2014.03+git20150611.fa71af2d
=======================================================
OpenGL Information
GL_VENDOR: NVIDIA Corporation
GL_RENDERER: NVIDIA Tegra X1 (nvgpu)/integrated
GL_VERSION: OpenGL ES 3.2 NVIDIA 32.7.1
=======================================================
[build] use-vbo=false: FPS: 2270 FrameTime: 0.441 ms
[build] use-vbo=true: FPS: 2901 FrameTime: 0.345 ms
[texture] texture-filter=nearest: FPS: 2724 FrameTime: 0.367 ms
[texture] texture-filter=linear: FPS: 2713 FrameTime: 0.369 ms
[texture] texture-filter=mipmap: FPS: 2773 FrameTime: 0.361 ms
[shading] shading=gouraud: FPS: 2295 FrameTime: 0.436 ms
[shading] shading=blinn-phong-inf: FPS: 2294 FrameTime: 0.436 ms
[shading] shading=phong: FPS: 2280 FrameTime: 0.439 ms
[shading] shading=cel: FPS: 2259 FrameTime: 0.443 ms
[bump] bump-render=high-poly: FPS: 1488 FrameTime: 0.672 ms
[bump] bump-render=normals: FPS: 3178 FrameTime: 0.315 ms
[bump] bump-render=height: FPS: 2907 FrameTime: 0.344 ms
[effect2d] kernel=0,1,0;1,-4,1;0,1,0;: FPS: 1541 FrameTime: 0.649 ms
[effect2d] kernel=1,1,1,1,1;1,1,1,1,1;1,1,1,1,1;: FPS: 747 FrameTime: 1.339 ms
[pulsar] light=false:quads=5:texture=false: FPS: 2883 FrameTime: 0.347 ms
[desktop] blur-radius=5:effect=blur:passes=1:separable=true:windows=4: FPS: 835 FrameTime: 1.198 ms
[desktop] effect=shadow:windows=4: FPS: 1395 FrameTime: 0.717 ms
[buffer] columns=200:interleave=false:update-dispersion=0.9:update-fraction=0.5:update-method=map: FPS: 418 FrameTime: 2.392 ms
[buffer] columns=200:interleave=false:update-dispersion=0.9:update-fraction=0.5:update-method=subdata: FPS: 449 FrameTime: 2.227 ms
[buffer] columns=200:interleave=true:update-dispersion=0.9:update-fraction=0.5:update-method=map: FPS: 490 FrameTime: 2.041 ms
[ideas] speed=duration: FPS: 1987 FrameTime: 0.503 ms
[jellyfish] : FPS: 1438 FrameTime: 0.695 ms
[terrain] : FPS: 144 FrameTime: 6.944 ms
[shadow] : FPS: 1964 FrameTime: 0.509 ms
[refract] : FPS: 323 FrameTime: 3.096 ms
[conditionals] fragment-steps=0:vertex-steps=0: FPS: 2994 FrameTime: 0.334 ms
[conditionals] fragment-steps=5:vertex-steps=0: FPS: 2522 FrameTime: 0.397 ms
[conditionals] fragment-steps=0:vertex-steps=5: FPS: 2993 FrameTime: 0.334 ms
[function] fragment-complexity=low:fragment-steps=5: FPS: 2890 FrameTime: 0.346 ms
[function] fragment-complexity=medium:fragment-steps=5: FPS: 2325 FrameTime: 0.430 ms
[loop] fragment-loop=false:fragment-steps=5:vertex-steps=5: FPS: 2884 FrameTime: 0.347 ms
[loop] fragment-steps=5:fragment-uniform=false:vertex-steps=5: FPS: 2884 FrameTime: 0.347 ms
[loop] fragment-steps=5:fragment-uniform=true:vertex-steps=5: FPS: 2445 FrameTime: 0.409 ms
=======================================================
glmark2 Score: 2019
=======================================================
5W
=======================================================
glmark2 2014.03+git20150611.fa71af2d
=======================================================
OpenGL Information
GL_VENDOR: NVIDIA Corporation
GL_RENDERER: NVIDIA Tegra X1 (nvgpu)/integrated
GL_VERSION: OpenGL ES 3.2 NVIDIA 32.7.1
=======================================================
[build] use-vbo=false: FPS: 1463 FrameTime: 0.684 ms
[build] use-vbo=true: FPS: 1927 FrameTime: 0.519 ms
[texture] texture-filter=nearest: FPS: 1850 FrameTime: 0.541 ms
[texture] texture-filter=linear: FPS: 1515 FrameTime: 0.660 ms
[texture] texture-filter=mipmap: FPS: 1880 FrameTime: 0.532 ms
[shading] shading=gouraud: FPS: 1648 FrameTime: 0.607 ms
[shading] shading=blinn-phong-inf: FPS: 1675 FrameTime: 0.597 ms
[shading] shading=phong: FPS: 1505 FrameTime: 0.664 ms
[shading] shading=cel: FPS: 1528 FrameTime: 0.654 ms
[bump] bump-render=high-poly: FPS: 995 FrameTime: 1.005 ms
[bump] bump-render=normals: FPS: 2119 FrameTime: 0.472 ms
[bump] bump-render=height: FPS: 2039 FrameTime: 0.490 ms
[effect2d] kernel=0,1,0;1,-4,1;0,1,0;: FPS: 1049 FrameTime: 0.953 ms
[effect2d] kernel=1,1,1,1,1;1,1,1,1,1;1,1,1,1,1;: FPS: 503 FrameTime: 1.988 ms
[pulsar] light=false:quads=5:texture=false: FPS: 1873 FrameTime: 0.534 ms
[desktop] blur-radius=5:effect=blur:passes=1:separable=true:windows=4: FPS: 575 FrameTime: 1.739 ms
[desktop] effect=shadow:windows=4: FPS: 815 FrameTime: 1.227 ms
[buffer] columns=200:interleave=false:update-dispersion=0.9:update-fraction=0.5:update-method=map: FPS: 287 FrameTime: 3.484 ms
[buffer] columns=200:interleave=false:update-dispersion=0.9:update-fraction=0.5:update-method=subdata: FPS: 311 FrameTime: 3.215 ms
[buffer] columns=200:interleave=true:update-dispersion=0.9:update-fraction=0.5:update-method=map: FPS: 370 FrameTime: 2.703 ms
[ideas] speed=duration: FPS: 1117 FrameTime: 0.895 ms
[jellyfish] : FPS: 981 FrameTime: 1.019 ms
[terrain] : FPS: 103 FrameTime: 9.709 ms
[shadow] : FPS: 1310 FrameTime: 0.763 ms
[refract] : FPS: 269 FrameTime: 3.717 ms
[conditionals] fragment-steps=0:vertex-steps=0: FPS: 2024 FrameTime: 0.494 ms
[conditionals] fragment-steps=5:vertex-steps=0: FPS: 1620 FrameTime: 0.617 ms
[conditionals] fragment-steps=0:vertex-steps=5: FPS: 2028 FrameTime: 0.493 ms
[function] fragment-complexity=low:fragment-steps=5: FPS: 1794 FrameTime: 0.557 ms
[function] fragment-complexity=medium:fragment-steps=5: FPS: 1513 FrameTime: 0.661 ms
[loop] fragment-loop=false:fragment-steps=5:vertex-steps=5: FPS: 1806 FrameTime: 0.554 ms
[loop] fragment-steps=5:fragment-uniform=false:vertex-steps=5: FPS: 1834 FrameTime: 0.545 ms
[loop] fragment-steps=5:fragment-uniform=true:vertex-steps=5: FPS: 1592 FrameTime: 0.628 ms
=======================================================
glmark2 Score: 1330
=======================================================


コメント